
একটি ডেটা ওয়্যারহাউস হল একটি কেন্দ্রীভূত সিস্টেম যা বিভিন্ন উৎস থেকে বিপুল পরিমাণ ডেটা সংরক্ষণ, সংগঠিত এবং বিশ্লেষণের জন্য ব্যবহৃত হয়। এটি বিশেষভাবে দৈনন্দিন লেনদেন প্রক্রিয়াকরণের পরিবর্তে অনুসন্ধান এবং প্রতিবেদনের জন্য ডিজাইন করা হয়েছে।
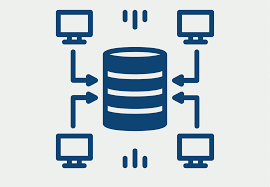
একটি ডেটা ওয়্যারহাউসের মূল বৈশিষ্ট্যগুলি এখানে দেওয়া হল:
- বিষয়-ভিত্তিক: বিক্রয়, গ্রাহক বা পণ্যের মতো গুরুত্বপূর্ণ বিষয়গুলিকে কেন্দ্র করে সংগঠিত।
- সমন্বিত: বিভিন্ন উৎস থেকে ডেটা একটি সুসংগত বিন্যাসে একত্রিত করে।
- অ-উদ্বায়ী: একবার ডেটা প্রবেশ করানো হলে, এটি পরিবর্তিত হয় না (ঐতিহাসিক বিশ্লেষণের জন্য ব্যবহৃত হয়)।
- সময়-পরিবর্তন: প্রবণতা, পূর্বাভাস এবং তুলনার জন্য ঐতিহাসিক ডেটা সংরক্ষণ করে।
ডেটা ওয়্যারহাউস মডেলিং হল একটি ডেটা ওয়্যারহাউসের কাঠামো ডিজাইন করার প্রক্রিয়া যাতে ডেটা দক্ষতার সাথে সংরক্ষণ, পুনরুদ্ধার এবং বিশ্লেষণ করা যায়। এটি এমনভাবে ডেটা সংগঠিত করার উপর দৃষ্টি নিবদ্ধ করে যা রিপোর্টিং, বিশ্লেষণ এবং ডেটা মাইনিংয়ের মতো ব্যবসায়িক বুদ্ধিমত্তা (BI) কার্যকলাপকে সমর্থন করে।
এখানে একটি সহজ ভাণ্ডার দেওয়া হল:
মূল ধারণা
১. ডেটা ওয়্যারহাউস: একটি কেন্দ্রীয় ভাণ্ডার যেখানে একাধিক উৎস থেকে ডেটা সংগ্রহ, সংরক্ষণ এবং বিশ্লেষণের জন্য উপলব্ধ করা হয়।
২. মডেলিং: এই ডেটার কাঠামোর নকশা – এটি কীভাবে সংগঠিত, সংযুক্ত এবং সংরক্ষণ করা হয়।
একটি ডেটা ওয়্যারহাউসে ডেটা মডেলের প্রকার
১. ধারণাগত মডেল
- উচ্চ-স্তরের ওভারভিউ।
- কোন ডেটা প্রয়োজন তার উপর দৃষ্টি নিবদ্ধ করে (যেমন, বিক্রয়, গ্রাহক) ।
- ব্যবসায়িক স্টেকহোল্ডারদের সাথে প্রাথমিক পরিকল্পনার সময় ব্যবহৃত হয়।
২. লজিক্যাল মডেল
- আরও বিস্তারিত।
- সম্পর্ক, কী, বৈশিষ্ট্য এবং ডেটা প্রকার সংজ্ঞায়িত করে।
- এখনও কোনও নির্দিষ্ট ডাটাবেসের সাথে আবদ্ধ নয়।
৩. ভৌত মডেল
- একটি ডাটাবেসে প্রকৃত বাস্তবায়ন (যেমন, SQL টেবিল) । সূচীকরণ, বিভাজন, কর্মক্ষমতা টিউনিং অন্তর্ভুক্ত।
ডেটা ওয়্যারহাউস স্কিমার প্রকারভেদ
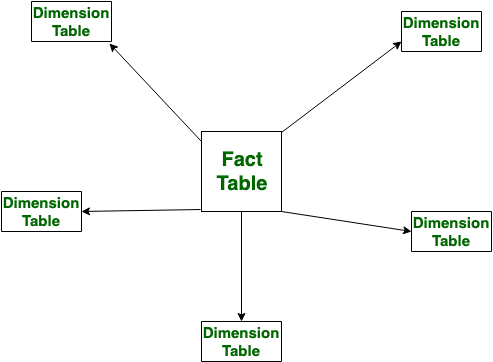
১. তারকা স্কিমা
- কেন্দ্রে ফ্যাক্ট টেবিল (পরিমাপযোগ্য ডেটা ধারণ করে)।
- ডাইমেনশন টেবিল (সময়, পণ্য, অবস্থানের মতো বর্ণনামূলক ডেটা) দ্বারা বেষ্টিত।
- সহজ, প্রশ্নের জন্য দ্রুত।
২. স্নোফ্লেক স্কিমা
- তারার মতো, কিন্তু ডাইমেনশন টেবিলগুলি স্বাভাবিক করা হয় (উপ-টেবিলে বিভক্ত) ।
- স্থান সাশ্রয় করে কিন্তু আরও যোগদানের কারণে ধীর হতে পারে।
৩. গ্যালাক্সি স্কিমা (ফ্যাক্ট কনস্টেলেশন)
- একাধিক ফ্যাক্ট টেবিল ডাইমেনশন টেবিল ভাগ করে।
- জটিল ডেটা গুদামে ব্যবহৃত হয়।
মডেলিং কেন গুরুত্বপূর্ণ?
- ডেটার ধারাবাহিকতা এবং অখণ্ডতা নিশ্চিত করে।
- কোয়েরি কর্মক্ষমতা অপ্টিমাইজ করে।
- রিপোর্টিং এবং বিশ্লেষণকে সহজ করে তোলে।
- ডেটা বৃদ্ধির জন্য স্কেলেবিলিটি সমর্থন করে।
মূল ধারণা (Key Concepts)
- Data Warehouse: একটি Central Repository, যেখানে বিভিন্ন উৎস (sources) থেকে আসা ডেটা একত্রিত করে রাখা হয় এবং বিশ্লেষণের জন্য প্রস্তুত করা হয়।
- Modelling: ডেটাকে কীভাবে সংরক্ষণ (store), সংযুক্ত (relate), এবং উপস্থাপন (present) করা হবে, সেই গঠন বা ডিজাইন প্রক্রিয়া।
Data Model-এর ধরন:-
1. Conceptual Model:
- এটি একটি High-Level Overview।
- এখানে ঠিক করা হয় কোন কোন ডেটার প্রয়োজন (যেমন: Sales, Customer info)।
- এটি ব্যবসায়িক ব্যবহারকারীদের সাথে প্রাথমিক আলোচনার সময় ব্যবহার হয়।
2. Logical Model:
- আরও বিস্তারিত Model।
- এটি Attribute, Key, Relationship এবং Data Type নির্ধারণ করে।
- ডেটাবেস নিরপেক্ষ (Not DB-specific)।
3. Physical Model:
- এটি Actual Database Implementation।
- এখানে Table, Index, Partitioning ইত্যাদি যুক্ত হয়।
ফ্যাক্ট বনাম ডাইমেনশন টেবিল
Table Type ব্যাখ্যা উদাহরণ
ফ্যাক্ট টেবিল পরিমাপযোগ্য ডেটা রাখে Sales Amount, Quantity
ডাইমেনশন বিবরণী তথ্য রাখে Product, Customer, Date
কেন Data Warehouse Modeling গুরুত্বপূর্ণ?
- ডেটার ধারাবাহিকতা ও সততা বজায় রাখে।
- Query performance অনেক ভালো হয়।
- রিপোর্টিং ,বিশ্লেষণ সহজ হয়।
- ভবিষ্যতে বড় পরিসরে Scale করা সম্ভব।
Star Schema-এর Visual Diagram
চল, সহজভাবে ব্যাখ্যা করি — Data Cube আর OLAP কী, এবং কীভাবে তারা Data Warehouse-এর সাথে সম্পর্কিত।
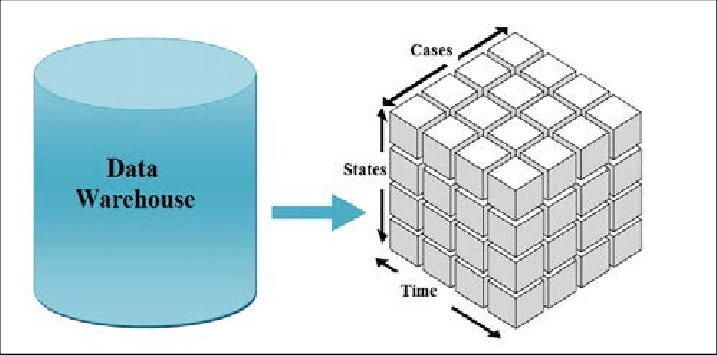
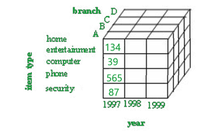
Data Cube কী?
Data Cube হলো একটি মাল্টি-ডাইমেনশনাল ডেটা স্ট্রাকচার, যেখানে ডেটা অনেকগুলি Dimension (দিক) অনুযায়ী সাজানো থাকে। এটা এমন একটা কিউবের মতো কল্পনা করতে পারো, যেখানে প্রতিটি দিক বা Axis কোনো একটা Dimension বোঝায় — যেমন Time, Location, Product।
উদাহরণ:
ধরো, তুমি একটি কোম্পানির Sales ডেটা বিশ্লেষণ করছো। এই কিউবে তিনটি Dimension থাকতে পারে:
- Time (বছর, মাস, দিন)
- Product (TV, Laptop, Mobile)
- Region (Kolkata, Tamluk , Egra)
এই তিনটির combination-এ তুমি Sales Amount দেখতে পাবে। যেমন:
- 2025 সালের জানুয়ারিতে Kolkata-তে TV বিক্রির মোট অঙ্ক কত?
এই ধরণের মাল্টি-ডাইমেনশনাল বিশ্লেষণের জন্যই Data Cube ব্যবহৃত হয়।
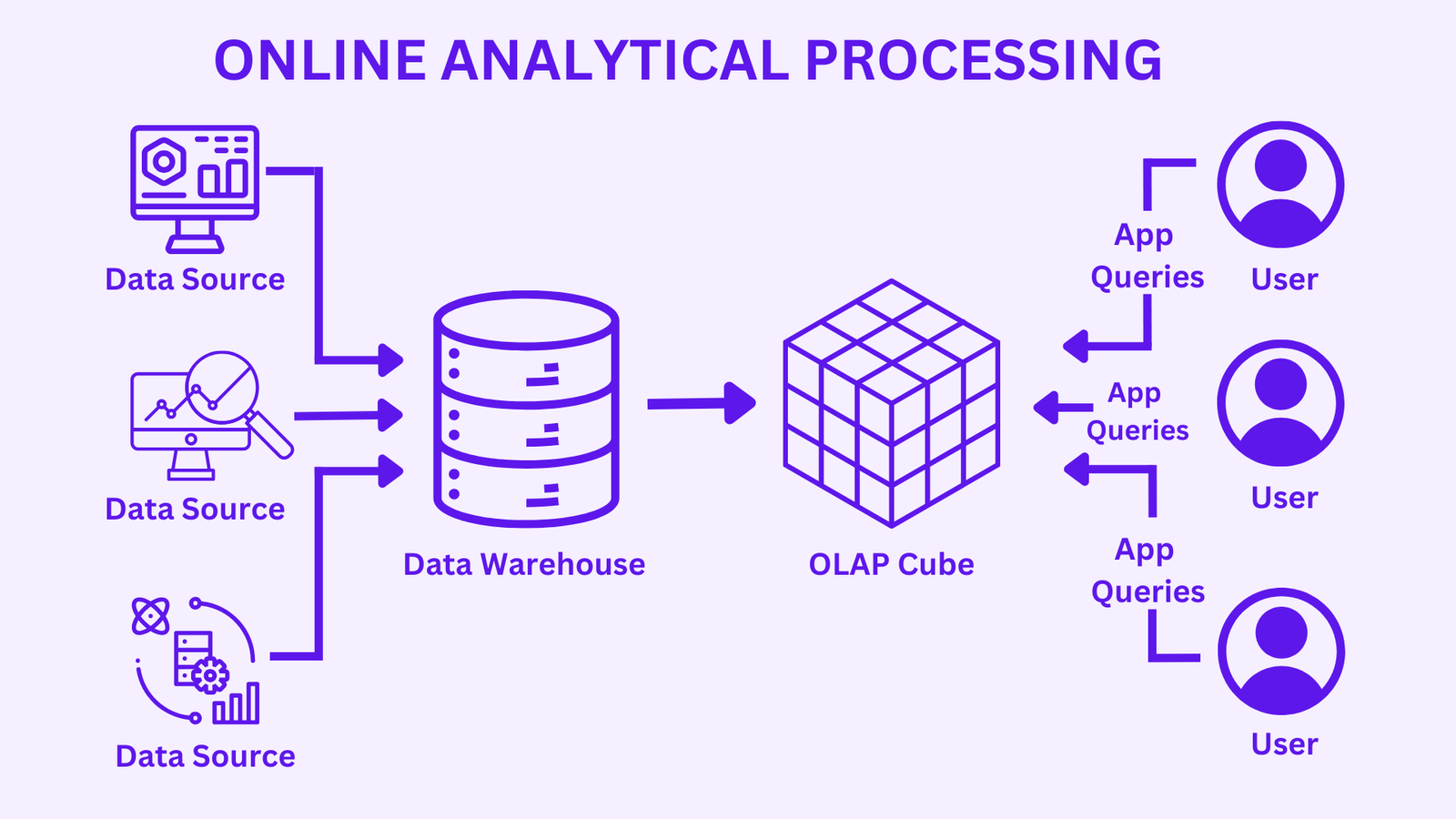
OLAP (Online Analytical Processing) কী?
OLAP হলো একটি প্রযুক্তি যা Data Cube-এর উপর দ্রুত বিশ্লেষণ চালানোর জন্য ব্যবহৃত হয়। এটি Business Intelligence-এর গুরুত্বপূর্ণ অংশ।
OLAP-এর মাধ্যমে ব্যবহারকারী ডেটাকে বিভিন্ন কোণ থেকে বিশ্লেষণ করতে পারে — খুব দ্রুত এবং Interactively।
OLAP Operation গুলো:
| Operation | ব্যাখ্যা (Description) |
| Roll-up | Higher level summary দেখা (e.g., মাস থেকে বছরে aggregate) |
| Drill-down | Detailed data দেখা (e.g., Region → City → Store) |
| Slice | এক Dimension ফিক্স করা (e.g., শুধু 2024 সালের data) |
| Dice | একাধিক Dimension ফিল্টার করা (e.g., 2024 + TV + Kolkata) |
| Pivot | Dimension ঘোরানো বা রি-অ্যারেঞ্জ করা (row ↔ column) |
OLAP-এর ধরণ
- MOLAP (Multidimensional OLAP):
- Pre-computed Cube ব্যবহার করে।
- Fast, কিন্তু বেশি storage লাগে।
- ROLAP (Relational OLAP):
- Traditional relational database ব্যবহার করে।
- Slow কিন্তু scalable।
- HOLAP (Hybrid OLAP):
- MOLAP আর ROLAP-এর মিশ্রণ।
কেন Data Cube ও OLAP দরকার?
- ব্যবসায়িক সিদ্ধান্ত গ্রহণকারীদের দ্রুত প্রশ্নের উত্তর পেতে সাহায্য করে।
- বিগ ডেটা-র বর্ণনা, প্যাটার্ন,
ও ব্যতিক্রম খুঁজে বের করা সহজ হয়। - বহুমাত্রিক তথ্য ভিজ্যুয়ালাইজেশন সম্ভব।
Data Warehouse Implementation মানে হলো — পুরো Data Warehouse System-টি বাস্তবে তৈরি ও চালু করা। এটা শুধু ডেটা রাখার জায়গা বানানো না, বরং পুরো এক্সট্র্যাকশন থেকে রিপোর্টিং পর্যন্ত পুরো প্রক্রিয়াটা তৈরি করা। চল, সহজভাবে ধাপে ধাপে দেখি:
ধাপসমূহ :
1. Requirement Analysis
- Business কী চায়, কোন ধরনের রিপোর্ট লাগবে, কোন কোন Source থেকে ডেটা আসবে — এসব বোঝা।
- Key Performance Indicators (KPIs) নির্ধারণ করা।
2. Data Warehouse Design
- Data Modelling করা (Star Schema / Snowflake Schema)
- Fact এবং Dimension Table নির্ধারণ।
- ETL Process (Extract, Transform, Load) এর প্ল্যান তৈরি।
3. ETL Development
- Extract: বিভিন্ন Source System থেকে ডেটা তোলা (যেমন: ERP, CRM)
- Transform: ডেটা ক্লিন করা, ফরম্যাট বদলানো, Business Logic apply করা
- Load: ডেটা Warehouse-এ লোড করা
ETL টুলের উদাহরণ: Talend, Informatica, Apache Nifi, Microsoft SSIS
4. Testing
- ডেটা নির্ভুলতা এবং গুণমান পরীক্ষা
- কর্মক্ষমতা পরীক্ষা (e.g., Query কত দ্রুত চলছে)
- সোর্স সিস্টেমের মাধ্যমে ডেটা ভ্যালিডেশন
5. OLAP & Reporting Layer
• OLAP কিউবস করা
• রিপোর্টিং টুল সংযোগ করা
• ড্যাশবোর্ড
6. স্থাপনা
• উৎপাদন পরিবেশ-এ লাইভ করা
• অ্যাক্সেস নিয়ন্ত্রণ ও নিরাপত্তা কনফিগারেশন
7. Maintenance & Monitoring
- ডেটা রিফ্রেশ ঠিকভাবে হচ্ছে কিনা দেখা
- পারফরম্যান্স টিউনিং
- সমস্যার সমাধান
সফল Implementation এর জন্য দরকার:
- ভালো Project Management
- স্পষ্ট Business Requirement
- দক্ষ ETL ও BI Developer
- ক্রমাগত প্রতিক্রিয়া এবং উন্নতি